|
|
You are here: Foswiki>ABI Web>LectureWiki>PMSB_Seqan_2015>PSMB_Seqan_2015_p5 (26 Mar 2015, cxpan)Edit Attach
PSMB_Seqan_2015_p5
Introduction
The q-gram(k-mer) Index in seqan allows looking up k-mers over the index in constant time. However it has two limitations. The first is, that if the k-mer is directly interpreted as an address in memory it limits its use to relatively small k. This can be addressed to some extend by using hashing schemes (like open addressing) to allow the storage of large size k-mers while sacrificing searching speed to some extent as a tradeoff. The second limitation is, that when we access in streaming mode neighbouring k-mers, they usually reside far apart in main memory, i.e. are not cache local. Here we try to make some improvements to the q-gram index by exploiting the potential ability of cpu caches. Cache is a smaller and faster memory acting a role of buffers between cpus and the main memory. Its working strategy exhibits strong locality of reference [1] indicating its potential for performance optimization. Reading-writing process in the cache can be extremely fast(Table). But it's time consuming to swap cache lines(a block of consistent bytes, usually 64 bytes in X64 cpu) from the main memory when cache miss occurs. Therefor it is reasonable to design strategies aiming at reducing the probability of cache miss to make use of caches. Here we utilize the concept of minimizers providing the possibility of making the q-gram index more cache friendly.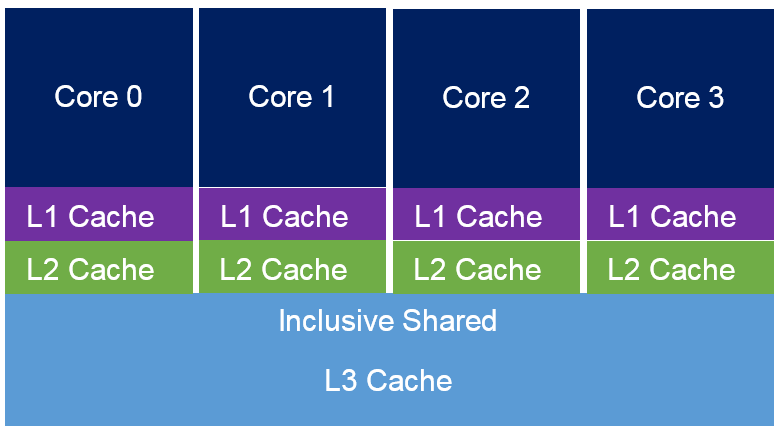
| L1 Cache | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | ~10-20 cycles | ~3-7 ns |
| L3 Cache | ~40-45 cycles | ~15 ns |
| Main memory | ~120-240 cycles | ~60-120 ns |
The purpose of introducing the concept of minimizers into sequence alignment is to cluster adjacent k-mers in memory. The origin concept of minimizer was defined as lexicographical minimum substring with fixed length[2]. The main idea of minimizer concept is adjacent k-mers in a sequence are very likely to share the same minimizer such that when searching k-mers from left to right in given sequences they are tending to fall into the same searching block already loaded into caches by their previous k-mers. However simple lexicographical minimum minimizes has its own defects. For an example it might create many unwanted contents swapped into caches increasing times of cache miss dramatically. These unwanted contents can be caused by nonadjacent k-mers but having same minimizers. Besides, other factors such as "too complex" strategy to acquire minimizers can also leads to this undesirable effects.
Tasks
Based on this, the objective of this task is to design and evaluate different strategies(functions) to choose minimizers. Generally, a minimizer function takes a k-mer as an input and returns its minimizer. Three relevant requirements for minimizer functions are enumerated in the following list. These are not definitions of minimizer functions but functions meeting these requirements might be more cache friendly or adaptable to q-gram index.- Adjacent k-mers tend to share the same minimizer while the nonadjacent k-mers do not
- Minimizers of given random k-mers are uniformly distributed
- It is easy to compute
Addition
The hash and hashNext function in seqan were overloaded to calculate minimizers. Time complexity of lexicographic minimizer hash is O(n). While time complexity of hashNext ranges from O(1) to O(n). It would be better if the time complexity of the new hashNext could be O(1), or at least no more than O(n). Clustering is one of the defects. Lexicographic minimizer results bias toward lexicographic smaller and low-complexity k-mer. For an example k-mer AA...A is more likely to be a minimizer than k-mer TT...T. Its better to keep each corresponding block of consistent k-mers created by minimizers at appropriate size. To be more specific, caches cant be utilized efficiently in too small size blocks because few adjacent k-mers in blocks can be loaded into caches. On the other hand too large size of blocks will be more time consuming for searching. Some simple operations might be worth consideration. For example minimizer := min xor max can reduce numbers of unwanted nonadjacent minimizers and create more uniformly distributed minimizers while still keeps the probability that adjacent k-mers share the same minimizes. Its defect is its more complex to calculate. Last but not least the cache performance does not only depend on how to choose minimizers. It is also very sensitive to how the function was programed. "Cache friendly" [3] programing is crucial to the final performance of the program. In other words the concept of minimizers might be able to enhance indexing structures generically, but adapting minimizers to these structures needs much more specific optimizations.Evaluation
New strategies developed will be assessed on the basis of a test data set. Several aspects of results like computing speed, distribution will be compared to those of lexicographical minimizer.Seqan Modules
The following parts of Seqan are relevant:- The I/O module:Sequence I/O
- The Q-gram module: Q-gram Index
References
- [1] Locality of reference
- [2] Reducing storage requirements for biological sequence comparison Roberts, M., Hayes, W., Hunt, B. R., Mount, S. M. and Yorke, J. A. (2004) Bioinformatics, 20, 33633369
- [3] Cache friendly code
Comments


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
dp_antidiag.png | manage | 22 K | 18 Mar 2015 - 15:24 | UnknownUser | |
| |
pmsb_2015_cache.png | manage | 15 K | 18 Mar 2015 - 15:37 | UnknownUser |
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r13 < r12 < r11 < r10 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r12 - 26 Mar 2015, cxpan
Ideas, requests, problems regarding Foswiki? Send feedback