|
|
You are here: Foswiki>ABI Web>WebPreferences>PMSB_Seqan_2018>LaganSeqan2018 (13 Apr 2018, jwinkler)Edit Attach
LArge Genome AligNer (LAGAN)
Hintergrund: Alignieren Genomischer Sequenzen
Durch das vergleichen zweier Genome unterschiedlicher Organismen können neue Erkenntnisse bezüglich der Konservierung funktionaler Einheiten gewonnen werden. Diese Erkenntnisse helfen uns Ursachen genetischer Krankheiten besser zu analysieren und zu verstehen. Um zwei biologische Sequenzen zu vergleichen wird ein globales Alignment berechnet. Dabei wird ermittelt welche Transformationen benötigt werden um eine Sequenz in die Andere zu überführen.
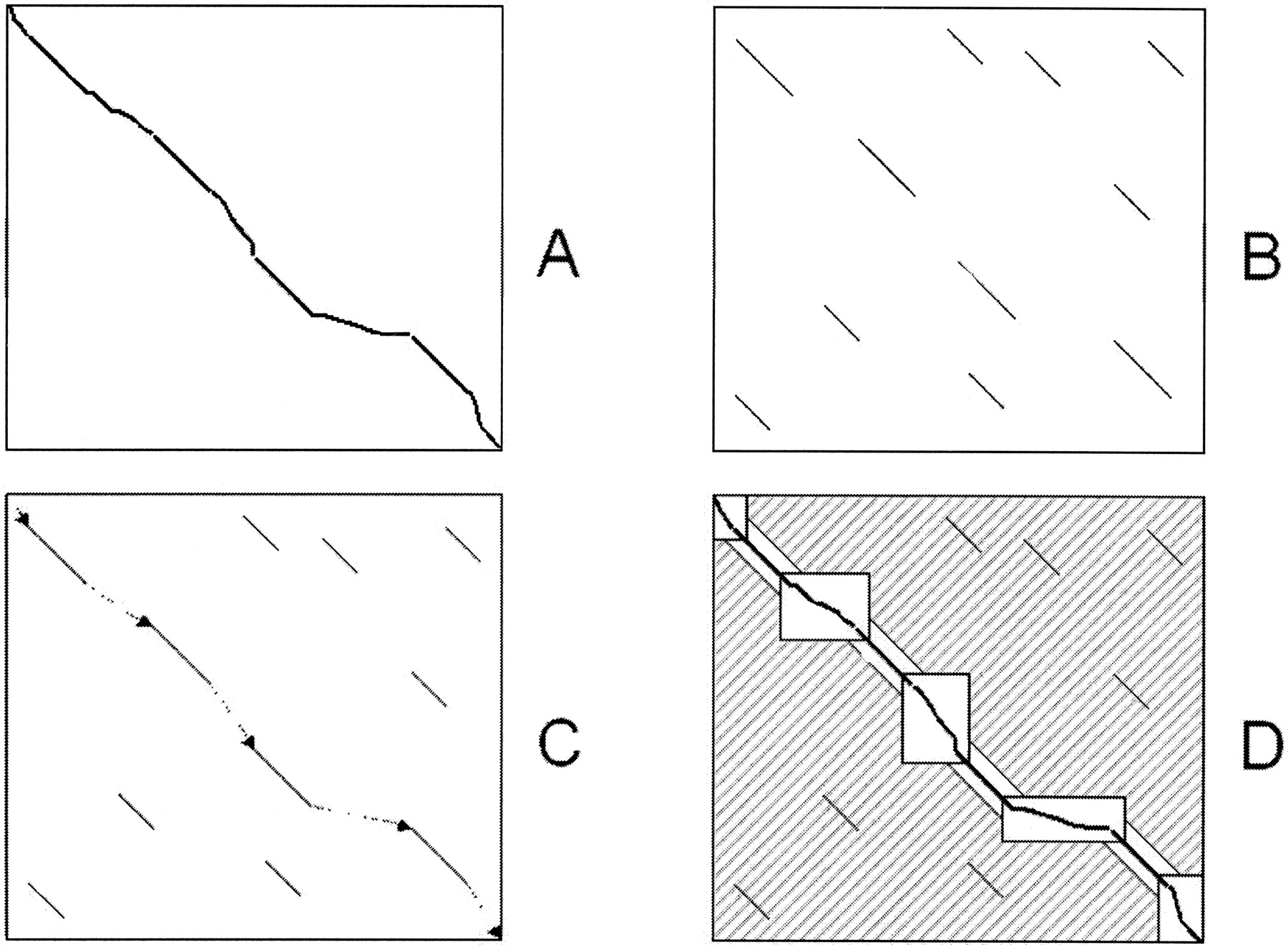 Jedoch ist das standard Global-Alignment-Verfahren [1] nicht geeignet um genomische Sequenzen zu alignieren, da sich seine Laufzeit proportional zum Produkt der beiden Sequenzlängen verhält. Alternativ können lokale Alignments [2, 3] berechnet werden um homologe Regionen zu identifizieren. Es lassen sich so jedoch kaum Zusammenhänge zwischen der gemeinsamen Ordnung der funktionalen Einheiten ableiten. Um effizient genomische Sequenzen global zu alignieren, werden Heuristiken benutzt, die zu erst gute lokale Segmente zwischen den beiden Sequenzen filtern und anschließend diese Informationen nutzen um daraus ein globales Alignment zu berechnen.
Jedoch ist das standard Global-Alignment-Verfahren [1] nicht geeignet um genomische Sequenzen zu alignieren, da sich seine Laufzeit proportional zum Produkt der beiden Sequenzlängen verhält. Alternativ können lokale Alignments [2, 3] berechnet werden um homologe Regionen zu identifizieren. Es lassen sich so jedoch kaum Zusammenhänge zwischen der gemeinsamen Ordnung der funktionalen Einheiten ableiten. Um effizient genomische Sequenzen global zu alignieren, werden Heuristiken benutzt, die zu erst gute lokale Segmente zwischen den beiden Sequenzen filtern und anschließend diese Informationen nutzen um daraus ein globales Alignment zu berechnen. Einer der bekanntesten Vertreter dieser Heuristiken is der LAGAN-Algorithmus [4]. Dieser besteht im wesentlichen aus 3 Schritten: B) Generieren von lokalen Alignments zwischen den beiden Genomen. C) Konstruieren einer globalen Map durch Chaining der identifizierten Segmente. D) Berechnen des optimalen Alignments innerhalb der Region definiert durch die globale Map aus.
Aufgaben
Ziel dieser Aufgabe ist es, eine einfache Version des LAGAN-Algorithmus zu implementieren. Eingabe des Programms sind zwei FASTA-Dateien mit den beiden Genomen, sowie die Parameter für das Seeding. Als Ausgabe soll das Programm das Alignment in eine Datei herausschreiben.Task 1: Indexaufbau
Im ersten Teil soll eine qGram-Index über die Datenbank aufgebaut werden. Die Größe der q-Gramme wird vom Nutzer übergeben.Task 2: Seeds finden
Anschließend wird die Query gescanned und die gefundenen Seeds in ein SeedSet eingefügt. Dabei soll zu Beginn die einfache merge Methode verwendet werden.Task 3: Chaining und Alignment
Aus dem erhaltenen SeedSet soll nun ein globale Chain [5] berechnet werden. Diese wird anschließend in mittels Banded-Chain-Alignment Algorithmus [4] zu einem globalen Alignment zusammengefügt.Zusatz
Option 1: CHAOS-Chaining:
Die Methode zum Zusammenführen von Seeds soll durch das CHAOS-Chaining [6] ersetzt werden, dabei muss auch die Eingabe an das Programm ersetzt werden.Option 2: Multiple Suchinstanzen
Im originalen LAGAN Algorithmus wird das Alignment wiederholt ausgeführt wobei in jedem Schritt die Parameter für das CHAOS-Chaining verändert werden, sodass die q-Gramme kleiner aber die erlaubte Fehlertoleranz größer wird. Zuerst wird dabei nach langen gut konservierten Regionen gesucht und in jedem weiteren Durchlauf nur noch die Bereiche zwischen den gefundenen Seeds mit relaxierten Parametern gesucht. Die Method soll dahingehen erweitert werden, dass sie ebenfalls mit 3 verschiedene CHAOS-Einstellungen berechnet werden kann.Evaluation
Die entwickelten Methoden sollen sinnvoll getestet werden. Das Programm soll anhand eines Testdatensatzes auf Richtigkeit geprüft werden. Dafür werden zwei Sequenzen generiert und anschließend zufällig erzeugte Seeds mit variabler Länge generiert. Jeder Seed wird zufällig in beide Sequenzen eingefügt und das Seed-Sequenz-Paar abgespeichert. Hinterher wird überprüft, ob korrekte Seed-Sequenz-Paare gefunden wurden. Im Anschluss soll der Algorithmus auf Realdaten angewendet werden. Je nach Fortschritt des Algorithmus sollen Sequenzen von verschiedenen Organismen verglichen werden:- 2 Phagen Genome (~10^4 bp)
- 2 Bakterien Genome (~10^6 bp)
- 2 Hefen Genome (~10^7 bp)
- 2 Drosophila Genome (~10^8 bp)
SeqAn Module
Die folgenden Teile von SeqAn sind relevant:- Das Seeds Modul: Seed and Extend.
- Das I/O-Modul: Sequence I/O.
- Das Index Modul: QGram-Index.
References
- [1] Needleman-Wunsch-Algorithmus
- [2] Smith-Waterman-Algorithmus
- [3] Basic Local Alignment Search Tool. Altschul, S.F., Gish, W., Miller, W., Myers, E.W., Lipman, D.J.(1990). J. Mol. Biol. 215:403–410.
- [4] LAGAN and Multi-LAGAN: Efficient Tools for Large-Scale Multiple Alignment of Genomic DNA. Brudno, M., et al. (2003). Genome Res. 2003. 13: 721-731. doi:10.1101/gr.926603
- [5] Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology. Gusfield, D., Cambridge, UK: Cambridge University Press; 1997
- [6] Fast and sensitive alignment of large genomic sequences. Brudno, M., Morgenstern, B., (2002). Bioinformatics Conference, 2002. Proceedings. IEEE Computer Society
Edit | Attach | Print version | History: r2 < r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r1 - 13 Apr 2018, jwinkler
Ideas, requests, problems regarding Foswiki? Send feedback