|
|
You are here: Foswiki>CompMolBio Web>DetailedBalance (03 Aug 2007, JanHendrikPrinz)Edit Attach
Page DetailedBalance
This is a discussion about the necessity of Detailed Balance in Markov ModelsDefinition
The probability of being in a state o at some time should be given by![\[p: (o,t) \longrightarrow p(o,t)\]](/wiki/pub/CompMolBio/DetailedBalance/latexd40fc22d51176de8ba9340629864d829.png)
 to a new state
to a new state 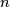 during a fixed time step, which is a single time step in the underlying discrete Markov Model.
during a fixed time step, which is a single time step in the underlying discrete Markov Model.
![\[J: (o,n) \longrightarrow J(o,n)\]](/wiki/pub/CompMolBio/DetailedBalance/latex624f0fdc7a0ed8baa56e929ec6a2bc23.png)
![\[p(o,t+1) = p(o,t) + \sum\limits_n [J(n \rightarrow o) - J(o \rightarrow n)]\]](/wiki/pub/CompMolBio/DetailedBalance/latex82c3991ec200a1ad26c5b962a89cdfdc.png)
![\[ p(o,t+1) = p(o,t)\]](/wiki/pub/CompMolBio/DetailedBalance/latexe9767651cdf620d77f6063156ad839fc.png)
![\[J(n \rightarrow o) = J(o \rightarrow n) \]](/wiki/pub/CompMolBio/DetailedBalance/latex0779c5e6a897bcb66b017d23eee429ec.png)
The connection to Markov Models and Monte Carlo Simulation
Since with Monte Carlo Simulation the stress is on sampling the stationary distribution and not on the dynamics anymore. The idea is to explore the phase space in a somewhat random fashion and reject states during this exploration with the right probability, so that the remaining time series represents the stationary distribution. This means, that in a MC algorithm a Probability Flux Matrix is constructed in such a way, that it will reproduce the right stationary distribution. To do this, the Flux from to
is seperated in three parts, with the main idea to introduce a trial move probability and
an acceptance probability -
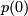 the probability of being in state
the probability of being in state
-
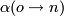 the probability of generating a the trial move from to
the probability of generating a the trial move from to
-
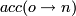 the probability of accepting the trial move from to
the probability of accepting the trial move from to
![\[J(o \rightarrow n) = p(o) \times \alpha(o \rightarrow n) \times acc(o \rightarrow n)\]](/wiki/pub/CompMolBio/DetailedBalance/latexaf1e58bd7311a7154af65b1ad0047fe8.png)
 . So
this part is given.
The proposal step probability can be chosen arbitrarily, although one uses usually a symmetric one
. So
this part is given.
The proposal step probability can be chosen arbitrarily, although one uses usually a symmetric one
![\[\alpha(o \rightarrow n) = \alpha(n \rightarrow o)\]](/wiki/pub/CompMolBio/DetailedBalance/latex05c5b6989f073204726153f22ffe416a.png)
![\[ \frac{acc(o \rightarrow n)}{acc(n \rightarrow o)} = \frac{\alpha(o \rightarrow n) p(n)}{\alpha(n \rightarrow o) p(o)} = \frac{\alpha(o \rightarrow n)}{\alpha(n \rightarrow o) }\times \exp(-\beta (U(n) - U(o)))\]](/wiki/pub/CompMolBio/DetailedBalance/latexfc3713f00cb9ad5c85c992c22af054d9.png)
![\[ acc(o \rightarrow n) = \min(1, \exp(-\beta (U(n) - U(o))))\]](/wiki/pub/CompMolBio/DetailedBalance/latex00d2ccac546215b43caee372b38d9d62.png)
- the simulation time to be long enough and
- the the proposed state to be statistically independant from the old state, which is
Comments
Edit | Attach | Print version | History: r3 < r2 < r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r2 - 03 Aug 2007, JanHendrikPrinz
Ideas, requests, problems regarding Foswiki? Send feedback