Sensititivy Analysis in the Degenerate Case for Perron-Eigenvalues
We use a paper from N. Singhal and V. Pande as reference and start from there. We proceed in analogy to appendix B. We extend the Sensitivity Analysis for the case, that an eigenvalue is degenerate. Since we are interested in the computation of the stationary distribution of a system, which has been sampled by short trajectories. This can lead to transition matrices, which do not have one unique Perron-Eigenvector, but a few, which correspond to completely seperated subspaces. In particular this can happen, when the trajectory is started in state, that are known to exist, but have not been observed by previous trajectories. We will concentrate only on the case, where the eigenvector subspace to the eigenvalue one is degenerated. In this particular case a few step even simplify.
To compute the stationary distribution we need to compute the left eigenvalues of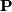 to the eigenvalue one or of
to the eigenvalue one or of 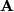 to the eigenvalue zero, which is equivalent to find a basis for the
kernel or the nullspace. To compute left eigenvalues, with an algorithmus
written for right eigenvalues, one needs to transpose the matrix in
question and proceed as usual.
We start with an eigenvector equation, where
to the eigenvalue zero, which is equivalent to find a basis for the
kernel or the nullspace. To compute left eigenvalues, with an algorithmus
written for right eigenvalues, one needs to transpose the matrix in
question and proceed as usual.
We start with an eigenvector equation, where 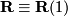 is the Matrix of right eigenvectors (in columns) to the eigenvalue
one and the
is the Matrix of right eigenvectors (in columns) to the eigenvalue
one and the 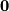 is a zeromatrix of the same size. In analogy
is a zeromatrix of the same size. In analogy
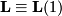 is the matrix of left eigenvectors
(in rows).
is the matrix of left eigenvectors
(in rows).
![\[ \mathbf{A}\mathbf{R}=\mathbf{0}_{R}\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex0205db8f07b8ae6fa4f6cc2004f6b99f.png)
![\[ \mathbf{L}\mathbf{A}=\mathbf{0}_{L}\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex97e50d13100f51c9533fb22bf5c2225c.png)
![\[ \sum_{k=1}^{b}r_{ik}r_{jk}=\left(\sum_{k=1}^{b}r_{ik}\right)\cdot\delta_{ij},\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex9a0f51cef8b0deaa963952979bc824b9.png)
![\[ \mathbf{R}^{T}\mathbf{R}=diag(c_{1},\ldots,c_{b})\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex6e7d61672e063cc1ce5393882c10c64e.png)
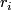 . The left eigenvectors indicate
now the stationary distribution inside one of these subspaces. To
proceed, we need to choose a basis of left eigenvectors, so that these
are also confined to the subspaces. We express this by
. The left eigenvectors indicate
now the stationary distribution inside one of these subspaces. To
proceed, we need to choose a basis of left eigenvectors, so that these
are also confined to the subspaces. We express this by
![\[ \sum_{k=1}^{b}l_{ik}r_{kj}=f_{i}\cdot\delta_{ij},\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex5dcbe46211ee62fa04d23fe105f12e26.png)
![\[ \mathbf{L}\mathbf{R}=diag(f_{1},\ldots,f_{b})\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex83a8ba88b45b95eba705faf479993612.png)
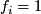 , so that the stationary distribution
in one subspace is given by
, so that the stationary distribution
in one subspace is given by 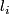 . This is equal to
. This is equal to![\[ ||l_{i}||_{1}=1\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latexf91c13feaaf5ab63daaf2ff7e867948a.png)
![\[ \mathbf{L}\mathbf{R}=\mathbf{1}\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex74ab63d0e36ce3490a5dd7b56688eff6.png) are constant
are constant![\[ \frac{\partial\mathbf{L}}{\partial p_{ij}}\mathbf{R}=0\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex6034a113ec1676b93bf99ed261a29a7f.png)
![\[ \frac{\partial\mathbf{L}}{\partial p_{ij}}\left[\begin{array}{cc} \bar{\mathbf{A}} & \mathbf{R}\end{array}\right]=\mathbf{L}\left[\begin{array}{cc} -\left(\frac{\partial\mathbf{A}}{\partial p_{ij}}-\sum_{k=1}^{b}\frac{\partial\lambda_{k}}{\partial p_{ij}}\mathbf{I}\right) & \mathbf{0}\end{array}\right]\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latexc221b571cbe2e167d5be4619f7bd3e9c.png)
![\[ \frac{\partial\mathbf{L}}{\partial p_{ij}}\left[\begin{array}{cc} \bar{\mathbf{A}} & \mathbf{R}\end{array}\right]=\mathbf{L}\left[\begin{array}{cc} -\left(e_{i}\left(e_{j}\right)^{T}-\left(\sum_{k=1}^{b}l_{jk}\right)\mathbf{1}\right) & \mathbf{0}\end{array}\right]\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex1412d1fbc4f3c660a8804e051a3f13c4.png)
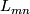 to
to 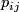 , when
, when 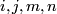 are in the same
subspace, otherwise the value is zero. At least I think, I have to
check that. At least I assume, when the degeneracy is maintained.
are in the same
subspace, otherwise the value is zero. At least I think, I have to
check that. At least I assume, when the degeneracy is maintained.
![\[ \frac{\partial l_{k}}{\partial p_{ij}}\left[\begin{array}{cc} \bar{\mathbf{A}} & \mathbf{R}\end{array}\right]=\mathbf{l_{k}}\left[\begin{array}{cc} -\left(e_{i}\left(e_{j}\right)^{T}-\left(\sum_{n=1}^{b}l_{jn}\right)\mathbf{1}\right) & \mathbf{0}\end{array}\right]\]](/wiki/pub/CompMolBio/EigenvectorSensitivity/latex48eeed5b15d7aa69e5c37a99e5cda17e.png)
Topic revision: 16 Aug 2007, JanHendrikPrinz
Ideas, requests, problems regarding Foswiki? Send feedback